



More on Personal Growth

Samer Buna
1 year ago
The Errors I Committed As a Novice Programmer
Learn to identify them, make habits to avoid them

First, a clarification. This article is aimed to make new programmers aware of their mistakes, train them to detect them, and remind them to prevent them.
I learned from all these blunders. I'm glad I have coding habits to avoid them. Do too.
These mistakes are not ordered.
1) Writing code haphazardly
Writing good content is hard. It takes planning and investigation. Quality programs don't differ.
Think. Research. Plan. Write. Validate. Modify. Unfortunately, no good acronym exists. Create a habit of doing the proper quantity of these activities.
As a newbie programmer, my biggest error was writing code without thinking or researching. This works for small stand-alone apps but hurts larger ones.
Like saying anything you might regret, you should think before coding something you could regret. Coding expresses your thoughts.
When angry, count to 10 before you speak. If very angry, a hundred. — Thomas Jefferson.
My quote:
When reviewing code, count to 10 before you refactor a line. If the code does not have tests, a hundred. — Samer Buna
Programming is primarily about reviewing prior code, investigating what is needed and how it fits into the current system, and developing small, testable features. Only 10% of the process involves writing code.
Programming is not writing code. Programming need nurturing.
2) Making excessive plans prior to writing code
Yes. Planning before writing code is good, but too much of it is bad. Water poisons.
Avoid perfect plans. Programming does not have that. Find a good starting plan. Your plan will change, but it helped you structure your code for clarity. Overplanning wastes time.
Only planning small features. All-feature planning should be illegal! The Waterfall Approach is a step-by-step system. That strategy requires extensive planning. This is not planning. Most software projects fail with waterfall. Implementing anything sophisticated requires agile changes to reality.
Programming requires responsiveness. You'll add waterfall plan-unthinkable features. You will eliminate functionality for reasons you never considered in a waterfall plan. Fix bugs and adjust. Be agile.
Plan your future features, though. Do it cautiously since too little or too much planning can affect code quality, which you must risk.
3) Underestimating the Value of Good Code
Readability should be your code's exclusive goal. Unintelligible code stinks. Non-recyclable.
Never undervalue code quality. Coding communicates implementations. Coders must explicitly communicate solution implementations.
Programming quote I like:
Always code as if the guy who ends up maintaining your code will be a violent psychopath who knows where you live. — John Woods
John, great advice!
Small things matter. If your indentation and capitalization are inconsistent, you should lose your coding license.
Long queues are also simple. Readability decreases after 80 characters. To highlight an if-statement block, you might put a long condition on the same line. No. Just never exceed 80 characters.
Linting and formatting tools fix many basic issues like this. ESLint and Prettier work great together in JavaScript. Use them.
Code quality errors:
Multiple lines in a function or file. Break long code into manageable bits. My rule of thumb is that any function with more than 10 lines is excessively long.
Double-negatives. Don't.
Using double negatives is just very not not wrong
Short, generic, or type-based variable names. Name variables clearly.
There are only two hard things in Computer Science: cache invalidation and naming things. — Phil Karlton
Hard-coding primitive strings and numbers without descriptions. If your logic relies on a constant primitive string or numeric value, identify it.
Avoiding simple difficulties with sloppy shortcuts and workarounds. Avoid evasion. Take stock.
Considering lengthier code better. Shorter code is usually preferable. Only write lengthier versions if they improve code readability. For instance, don't utilize clever one-liners and nested ternary statements just to make the code shorter. In any application, removing unneeded code is better.
Measuring programming progress by lines of code is like measuring aircraft building progress by weight. — Bill Gates
Excessive conditional logic. Conditional logic is unnecessary for most tasks. Choose based on readability. Measure performance before optimizing. Avoid Yoda conditions and conditional assignments.
4) Selecting the First Approach
When I started programming, I would solve an issue and move on. I would apply my initial solution without considering its intricacies and probable shortcomings.
After questioning all the solutions, the best ones usually emerge. If you can't think of several answers, you don't grasp the problem.
Programmers do not solve problems. Find the easiest solution. The solution must work well and be easy to read, comprehend, and maintain.
There are two ways of constructing a software design. One way is to make it so simple that there are obviously no deficiencies, and the other way is to make it so complicated that there are no obvious deficiencies. — C.A.R. Hoare
5) Not Giving Up
I generally stick with the original solution even though it may not be the best. The not-quitting mentality may explain this. This mindset is helpful for most things, but not programming. Program writers should fail early and often.
If you doubt a solution, toss it and rethink the situation. No matter how much you put in that solution. GIT lets you branch off and try various solutions. Use it.
Do not be attached to code because of how much effort you put into it. Bad code needs to be discarded.
6) Avoiding Google
I've wasted time solving problems when I should have researched them first.
Unless you're employing cutting-edge technology, someone else has probably solved your problem. Google It First.
Googling may discover that what you think is an issue isn't and that you should embrace it. Do not presume you know everything needed to choose a solution. Google surprises.
But Google carefully. Newbies also copy code without knowing it. Use only code you understand, even if it solves your problem.
Never assume you know how to code creatively.
The most dangerous thought that you can have as a creative person is to think that you know what you’re doing. — Bret Victor
7) Failing to Use Encapsulation
Not about object-oriented paradigm. Encapsulation is always useful. Unencapsulated systems are difficult to maintain.
An application should only handle a feature once. One object handles that. The application's other objects should only see what's essential. Reducing application dependencies is not about secrecy. Following these guidelines lets you safely update class, object, and function internals without breaking things.
Classify logic and state concepts. Class means blueprint template. Class or Function objects are possible. It could be a Module or Package.
Self-contained tasks need methods in a logic class. Methods should accomplish one thing well. Similar classes should share method names.
As a rookie programmer, I didn't always establish a new class for a conceptual unit or recognize self-contained units. Newbie code has a Util class full of unrelated code. Another symptom of novice code is when a small change cascades and requires numerous other adjustments.
Think before adding a method or new responsibilities to a method. Time's needed. Avoid skipping or refactoring. Start right.
High Cohesion and Low Coupling involves grouping relevant code in a class and reducing class dependencies.
8) Arranging for Uncertainty
Thinking beyond your solution is appealing. Every line of code will bring up what-ifs. This is excellent for edge cases but not for foreseeable needs.
Your what-ifs must fall into one of these two categories. Write only code you need today. Avoid future planning.
Writing a feature for future use is improper. No.
Write only the code you need today for your solution. Handle edge-cases, but don't introduce edge-features.
Growth for the sake of growth is the ideology of the cancer cell. — Edward Abbey
9) Making the incorrect data structure choices
Beginner programmers often overemphasize algorithms when preparing for interviews. Good algorithms should be identified and used when needed, but memorizing them won't make you a programming genius.
However, learning your language's data structures' strengths and shortcomings will make you a better developer.
The improper data structure shouts "newbie coding" here.
Let me give you a few instances of data structures without teaching you:
Managing records with arrays instead of maps (objects).
Most data structure mistakes include using lists instead of maps to manage records. Use a map to organize a list of records.
This list of records has an identifier to look up each entry. Lists for scalar values are OK and frequently superior, especially if the focus is pushing values to the list.
Arrays and objects are the most common JavaScript list and map structures, respectively (there is also a map structure in modern JavaScript).
Lists over maps for record management often fail. I recommend always using this point, even though it only applies to huge collections. This is crucial because maps are faster than lists in looking up records by identifier.
Stackless
Simple recursive functions are often tempting when writing recursive programming. In single-threaded settings, optimizing recursive code is difficult.
Recursive function returns determine code optimization. Optimizing a recursive function that returns two or more calls to itself is harder than optimizing a single call.
Beginners overlook the alternative to recursive functions. Use Stack. Push function calls to a stack and start popping them out to traverse them back.
10) Worsening the current code
Imagine this:

Add an item to that room. You might want to store that object anywhere as it's a mess. You can finish in seconds.
Not with messy code. Do not worsen! Keep the code cleaner than when you started.
Clean the room above to place the new object. If the item is clothing, clear a route to the closet. That's proper execution.
The following bad habits frequently make code worse:
code duplication You are merely duplicating code and creating more chaos if you copy/paste a code block and then alter just the line after that. This would be equivalent to adding another chair with a lower base rather than purchasing a new chair with a height-adjustable seat in the context of the aforementioned dirty room example. Always keep abstraction in mind, and use it when appropriate.
utilizing configuration files not at all. A configuration file should contain the value you need to utilize if it may differ in certain circumstances or at different times. A configuration file should contain a value if you need to use it across numerous lines of code. Every time you add a new value to the code, simply ask yourself: "Does this value belong in a configuration file?" The most likely response is "yes."
using temporary variables and pointless conditional statements. Every if-statement represents a logic branch that should at the very least be tested twice. When avoiding conditionals doesn't compromise readability, it should be done. The main issue with this is that branch logic is being used to extend an existing function rather than creating a new function. Are you altering the code at the appropriate level, or should you go think about the issue at a higher level every time you feel you need an if-statement or a new function variable?
This code illustrates superfluous if-statements:
function isOdd(number) {
if (number % 2 === 1) {
return true;
} else {
return false;
}
}Can you spot the biggest issue with the isOdd function above?
Unnecessary if-statement. Similar code:
function isOdd(number) {
return (number % 2 === 1);
};11) Making remarks on things that are obvious
I've learnt to avoid comments. Most code comments can be renamed.
instead of:
// This function sums only odd numbers in an array
const sum = (val) => {
return val.reduce((a, b) => {
if (b % 2 === 1) { // If the current number is odd
a+=b; // Add current number to accumulator
}
return a; // The accumulator
}, 0);
};Commentless code looks like this:
const sumOddValues = (array) => {
return array.reduce((accumulator, currentNumber) => {
if (isOdd(currentNumber)) {
return accumulator + currentNumber;
}
return accumulator;
}, 0);
};Better function and argument names eliminate most comments. Remember that before commenting.
Sometimes you have to use comments to clarify the code. This is when your comments should answer WHY this code rather than WHAT it does.
Do not write a WHAT remark to clarify the code. Here are some unnecessary comments that clutter code:
// create a variable and initialize it to 0
let sum = 0;
// Loop over array
array.forEach(
// For each number in the array
(number) => {
// Add the current number to the sum variable
sum += number;
}
);Avoid that programmer. Reject that code. Remove such comments if necessary. Most importantly, teach programmers how awful these remarks are. Tell programmers who publish remarks like this that they may lose their jobs. That terrible.
12) Skipping tests
I'll simplify. If you develop code without tests because you think you're an excellent programmer, you're a rookie.
If you're not writing tests in code, you're probably testing manually. Every few lines of code in a web application will be refreshed and interacted with. Also. Manual code testing is fine. To learn how to automatically test your code, manually test it. After testing your application, return to your code editor and write code to automatically perform the same interaction the next time you add code.
Human. After each code update, you will forget to test all successful validations. Automate it!
Before writing code to fulfill validations, guess or design them. TDD is real. It improves your feature design thinking.
If you can use TDD, even partially, do so.
13) Making the assumption that if something is working, it must be right.
See this sumOddValues function. Is it flawed?
const sumOddValues = (array) => {
return array.reduce((accumulator, currentNumber) => {
if (currentNumber % 2 === 1) {
return accumulator + currentNumber;
}
return accumulator;
});
};
console.assert(
sumOddValues([1, 2, 3, 4, 5]) === 9
);Verified. Good life. Correct?
Code above is incomplete. It handles some scenarios correctly, including the assumption used, but it has many other issues. I'll list some:
#1: No empty input handling. What happens when the function is called without arguments? That results in an error revealing the function's implementation:
TypeError: Cannot read property 'reduce' of undefined.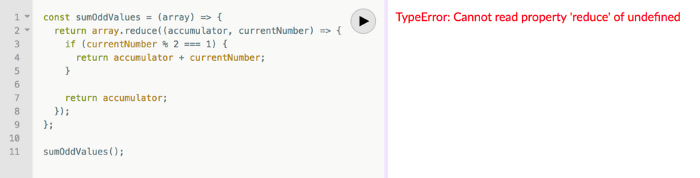
Two main factors indicate faulty code.
Your function's users shouldn't come across implementation-related information.
The user cannot benefit from the error. Simply said, they were unable to use your function. They would be aware that they misused the function if the error was more obvious about the usage issue. You might decide to make the function throw a custom exception, for instance:
TypeError: Cannot execute function for empty list.Instead of returning an error, your method should disregard empty input and return a sum of 0. This case requires action.
Problem #2: No input validation. What happens if the function is invoked with a text, integer, or object instead of an array?
The function now throws:
sumOddValues(42);
TypeError: array.reduce is not a functionUnfortunately, array. cut's a function!
The function labels anything you call it with (42 in the example above) as array because we named the argument array. The error says 42.reduce is not a function.
See how that error confuses? An mistake like:
TypeError: 42 is not an array, dude.Edge-cases are #1 and #2. These edge-cases are typical, but you should also consider less obvious ones. Negative numbers—what happens?
sumOddValues([1, 2, 3, 4, 5, -13]) // => still 9-13's unusual. Is this the desired function behavior? Error? Should it sum negative numbers? Should it keep ignoring negative numbers? You may notice the function should have been titled sumPositiveOddNumbers.
This decision is simple. The more essential point is that if you don't write a test case to document your decision, future function maintainers won't know if you ignored negative values intentionally or accidentally.
It’s not a bug. It’s a feature. — Someone who forgot a test case
#3: Valid cases are not tested. Forget edge-cases, this function mishandles a straightforward case:
sumOddValues([2, 1, 3, 4, 5]) // => 11The 2 above was wrongly included in sum.
The solution is simple: reduce accepts a second input to initialize the accumulator. Reduce will use the first value in the collection as the accumulator if that argument is not provided, like in the code above. The sum included the test case's first even value.
This test case should have been included in the tests along with many others, such as all-even numbers, a list with 0 in it, and an empty list.
Newbie code also has rudimentary tests that disregard edge-cases.
14) Adhering to Current Law
Unless you're a lone supercoder, you'll encounter stupid code. Beginners don't identify it and assume it's decent code because it works and has been in the codebase for a while.
Worse, if the terrible code uses bad practices, the newbie may be enticed to use them elsewhere in the codebase since they learnt them from good code.
A unique condition may have pushed the developer to write faulty code. This is a nice spot for a thorough note that informs newbies about that condition and why the code is written that way.
Beginners should presume that undocumented code they don't understand is bad. Ask. Enquire. Blame it!
If the code's author is dead or can't remember it, research and understand it. Only after understanding the code can you judge its quality. Before that, presume nothing.
15) Being fixated on best practices
Best practices damage. It suggests no further research. Best practice ever. No doubts!
No best practices. Today's programming language may have good practices.
Programming best practices are now considered bad practices.
Time will reveal better methods. Focus on your strengths, not best practices.
Do not do anything because you read a quote, saw someone else do it, or heard it is a recommended practice. This contains all my article advice! Ask questions, challenge theories, know your options, and make informed decisions.
16) Being preoccupied with performance
Premature optimization is the root of all evil (or at least most of it) in programming — Donald Knuth (1974)
I think Donald Knuth's advice is still relevant today, even though programming has changed.
Do not optimize code if you cannot measure the suspected performance problem.
Optimizing before code execution is likely premature. You may possibly be wasting time optimizing.
There are obvious optimizations to consider when writing new code. You must not flood the event loop or block the call stack in Node.js. Remember this early optimization. Will this code block the call stack?
Avoid non-obvious code optimization without measurements. If done, your performance boost may cause new issues.
Stop optimizing unmeasured performance issues.
17) Missing the End-User Experience as a Goal
How can an app add a feature easily? Look at it from your perspective or in the existing User Interface. Right? Add it to the form if the feature captures user input. Add it to your nested menu of links if it adds a link to a page.
Avoid that developer. Be a professional who empathizes with customers. They imagine this feature's consumers' needs and behavior. They focus on making the feature easy to find and use, not just adding it to the software.
18) Choosing the incorrect tool for the task
Every programmer has their preferred tools. Most tools are good for one thing and bad for others.
The worst tool for screwing in a screw is a hammer. Do not use your favorite hammer on a screw. Don't use Amazon's most popular hammer on a screw.
A true beginner relies on tool popularity rather than problem fit.
You may not know the best tools for a project. You may know the best tool. However, it wouldn't rank high. You must learn your tools and be open to new ones.
Some coders shun new tools. They like their tools and don't want to learn new ones. I can relate, but it's wrong.
You can build a house slowly with basic tools or rapidly with superior tools. You must learn and use new tools.
19) Failing to recognize that data issues are caused by code issues
Programs commonly manage data. The software will add, delete, and change records.
Even the simplest programming errors can make data unpredictable. Especially if the same defective application validates all data.
Code-data relationships may be confusing for beginners. They may employ broken code in production since feature X is not critical. Buggy coding may cause hidden data integrity issues.
Worse, deploying code that corrected flaws without fixing minor data problems caused by these defects will only collect more data problems that take the situation into the unrecoverable-level category.
How do you avoid these issues? Simply employ numerous data integrity validation levels. Use several interfaces. Front-end, back-end, network, and database validations. If not, apply database constraints.
Use all database constraints when adding columns and tables:
If a column has a NOT NULL constraint, null values will be rejected for that column. If your application expects that field has a value, your database should designate its source as not null.
If a column has a UNIQUE constraint, the entire table cannot include duplicate values for that column. This is ideal for a username or email field on a Users table, for instance.
For the data to be accepted, a CHECK constraint, or custom expression, must evaluate to true. For instance, you can apply a check constraint to ensure that the values of a normal % column must fall within the range of 0 and 100.
With a PRIMARY KEY constraint, the values of the columns must be both distinct and not null. This one is presumably what you're utilizing. To distinguish the records in each table, the database needs have a primary key.
A FOREIGN KEY constraint requires that the values in one database column, typically a primary key, match those in another table column.
Transaction apathy is another data integrity issue for newbies. If numerous actions affect the same data source and depend on each other, they must be wrapped in a transaction that can be rolled back if one fails.
20) Reinventing the Wheel
Tricky. Some programming wheels need reinvention. Programming is undefined. New requirements and changes happen faster than any team can handle.
Instead of modifying the wheel we all adore, maybe we should rethink it if you need a wheel that spins at varied speeds depending on the time of day. If you don't require a non-standard wheel, don't reinvent it. Use the darn wheel.
Wheel brands can be hard to choose from. Research and test before buying! Most software wheels are free and transparent. Internal design quality lets you evaluate coding wheels. Try open-source wheels. Debug and fix open-source software simply. They're easily replaceable. In-house support is also easy.
If you need a wheel, don't buy a new automobile and put your maintained car on top. Do not include a library to use a few functions. Lodash in JavaScript is the finest example. Import shuffle to shuffle an array. Don't import lodash.
21) Adopting the incorrect perspective on code reviews
Beginners often see code reviews as criticism. Dislike them. Not appreciated. Even fear them.
Incorrect. If so, modify your mindset immediately. Learn from every code review. Salute them. Observe. Most crucial, thank reviewers who teach you.
Always learning code. Accept it. Most code reviews teach something new. Use these for learning.
You may need to correct the reviewer. If your code didn't make that evident, it may need to be changed. If you must teach your reviewer, remember that teaching is one of the most enjoyable things a programmer can do.
22) Not Using Source Control
Newbies often underestimate Git's capabilities.
Source control is more than sharing your modifications. It's much bigger. Clear history is source control. The history of coding will assist address complex problems. Commit messages matter. They are another way to communicate your implementations, and utilizing them with modest commits helps future maintainers understand how the code got where it is.
Commit early and often with present-tense verbs. Summarize your messages but be detailed. If you need more than a few lines, your commit is too long. Rebase!
Avoid needless commit messages. Commit summaries should not list new, changed, or deleted files. Git commands can display that list from the commit object. The summary message would be noise. I think a big commit has many summaries per file altered.
Source control involves discoverability. You can discover the commit that introduced a function and see its context if you doubt its need or design. Commits can even pinpoint which code caused a bug. Git has a binary search within commits (bisect) to find the bug-causing commit.
Source control can be used before commits to great effect. Staging changes, patching selectively, resetting, stashing, editing, applying, diffing, reversing, and others enrich your coding flow. Know, use, and enjoy them.
I consider a Git rookie someone who knows less functionalities.
23) Excessive Use of Shared State
Again, this is not about functional programming vs. other paradigms. That's another article.
Shared state is problematic and should be avoided if feasible. If not, use shared state as little as possible.
As a new programmer, I didn't know that all variables represent shared states. All variables in the same scope can change its data. Global scope reduces shared state span. Keep new states in limited scopes and avoid upward leakage.
When numerous resources modify common state in the same event loop tick, the situation becomes severe (in event-loop-based environments). Races happen.
This shared state race condition problem may encourage a rookie to utilize a timer, especially if they have a data lock issue. Red flag. No. Never accept it.
24) Adopting the Wrong Mentality Toward Errors
Errors are good. Progress. They indicate a simple way to improve.
Expert programmers enjoy errors. Newbies detest them.
If these lovely red error warnings irritate you, modify your mindset. Consider them helpers. Handle them. Use them to advance.
Some errors need exceptions. Plan for user-defined exceptions. Ignore some mistakes. Crash and exit the app.
25) Ignoring rest periods
Humans require mental breaks. Take breaks. In the zone, you'll forget breaks. Another symptom of beginners. No compromises. Make breaks mandatory in your process. Take frequent pauses. Take a little walk to plan your next move. Reread the code.
This has been a long post. You deserve a break.


Zuzanna Sieja
1 year ago
In 2022, each data scientist needs to read these 11 books.

Non-technical talents can benefit data scientists in addition to statistics and programming.
As our article 5 Most In-Demand Skills for Data Scientists shows, being business-minded is useful. How can you get such a diverse skill set? We've compiled a list of helpful resources.
Data science, data analysis, programming, and business are covered. Even a few of these books will make you a better data scientist.
Ready? Let’s dive in.
Best books for data scientists
1. The Black Swan
Author: Nassim Taleb

First, a less obvious title. Nassim Nicholas Taleb's seminal series examines uncertainty, probability, risk, and decision-making.
Three characteristics define a black swan event:
It is erratic.
It has a significant impact.
Many times, people try to come up with an explanation that makes it seem more predictable than it actually was.
People formerly believed all swans were white because they'd never seen otherwise. A black swan in Australia shattered their belief.
Taleb uses this incident to illustrate how human thinking mistakes affect decision-making. The book teaches readers to be aware of unpredictability in the ever-changing IT business.
Try multiple tactics and models because you may find the answer.
2. High Output Management
Author: Andrew Grove

Intel's former chairman and CEO provides his insights on developing a global firm in this business book. We think Grove would choose “management” to describe the talent needed to start and run a business.
That's a skill for CEOs, techies, and data scientists. Grove writes on developing productive teams, motivation, real-life business scenarios, and revolutionizing work.
Five lessons:
Every action is a procedure.
Meetings are a medium of work
Manage short-term goals in accordance with long-term strategies.
Mission-oriented teams accelerate while functional teams increase leverage.
Utilize performance evaluations to enhance output.
So — if the above captures your imagination, it’s well worth getting stuck in.
3. The Hard Thing About Hard Things: Building a Business When There Are No Easy Answers
Author: Ben Horowitz

Few realize how difficult it is to run a business, even though many see it as a tremendous opportunity.
Business schools don't teach managers how to handle the toughest difficulties; they're usually on their own. So Ben Horowitz wrote this book.
It gives tips on creating and maintaining a new firm and analyzes the hurdles CEOs face.
Find suggestions on:
create software
Run a business.
Promote a product
Obtain resources
Smart investment
oversee daily operations
This book will help you cope with tough times.
4. Obviously Awesome: How to Nail Product Positioning
Author: April Dunford

Your job as a data scientist is a product. You should be able to sell what you do to clients. Even if your product is great, you must convince them.
How to? April Dunford's advice: Her book explains how to connect with customers by making your offering seem like a secret sauce.
You'll learn:
Select the ideal market for your products.
Connect an audience to the value of your goods right away.
Take use of three positioning philosophies.
Utilize market trends to aid purchasers
5. The Mom test
Author: Rob Fitzpatrick

The Mom Test improves communication. Client conversations are rarely predictable. The book emphasizes one of the most important communication rules: enquire about specific prior behaviors.
Both ways work. If a client has suggestions or demands, listen carefully and ensure everyone understands. The book is packed with client-speaking tips.
6. Introduction to Machine Learning with Python: A Guide for Data Scientists
Authors: Andreas C. Müller, Sarah Guido

Now, technical documents.
This book is for Python-savvy data scientists who wish to learn machine learning. Authors explain how to use algorithms instead of math theory.
Their technique is ideal for developers who wish to study machine learning basics and use cases. Sci-kit-learn, NumPy, SciPy, pandas, and Jupyter Notebook are covered beyond Python.
If you know machine learning or artificial neural networks, skip this.
7. Python Data Science Handbook: Essential Tools for Working with Data
Author: Jake VanderPlas

Data work isn't easy. Data manipulation, transformation, cleansing, and visualization must be exact.
Python is a popular tool. The Python Data Science Handbook explains everything. The book describes how to utilize Pandas, Numpy, Matplotlib, Scikit-Learn, and Jupyter for beginners.
The only thing missing is a way to apply your learnings.
8. Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython
Author: Wes McKinney

The author leads you through manipulating, processing, cleaning, and analyzing Python datasets using NumPy, Pandas, and IPython.
The book's realistic case studies make it a great resource for Python or scientific computing beginners. Once accomplished, you'll uncover online analytics, finance, social science, and economics solutions.
9. Data Science from Scratch
Author: Joel Grus

Here's a title for data scientists with Python, stats, maths, and algebra skills (alongside a grasp of algorithms and machine learning). You'll learn data science's essential libraries, frameworks, modules, and toolkits.
The author works through all the key principles, providing you with the practical abilities to develop simple code. The book is appropriate for intermediate programmers interested in data science and machine learning.
Not that prior knowledge is required. The writing style matches all experience levels, but understanding will help you absorb more.
10. Machine Learning Yearning
Author: Andrew Ng

Andrew Ng is a machine learning expert. Co-founded and teaches at Stanford. This free book shows you how to structure an ML project, including recognizing mistakes and building in complex contexts.
The book delivers knowledge and teaches how to apply it, so you'll know how to:
Determine the optimal course of action for your ML project.
Create software that is more effective than people.
Recognize when to use end-to-end, transfer, and multi-task learning, and how to do so.
Identifying machine learning system flaws
Ng writes easy-to-read books. No rigorous math theory; just a terrific approach to understanding how to make technical machine learning decisions.
11. Deep Learning with PyTorch Step-by-Step
Author: Daniel Voigt Godoy

The last title is also the most recent. The book was revised on 23 January 2022 to discuss Deep Learning and PyTorch, a Python coding tool.
It comprises four parts:
Fundamentals (gradient descent, training linear and logistic regressions in PyTorch)
Machine Learning (deeper models and activation functions, convolutions, transfer learning, initialization schemes)
Sequences (RNN, GRU, LSTM, seq2seq models, attention, self-attention, transformers)
Automatic Language Recognition (tokenization, embeddings, contextual word embeddings, ELMo, BERT, GPT-2)
We admire the book's readability. The author avoids difficult mathematical concepts, making the material feel like a conversation.
Is every data scientist a humanist?
Even as a technological professional, you can't escape human interaction, especially with clients.
We hope these books will help you develop interpersonal skills.

James White
1 year ago
Three Books That Can Change Your Life in a Day
I've summarized each.

Anne Lamott said books are important. Books help us understand ourselves and our behavior. They teach us about community, friendship, and death.
I read. One of my few life-changing habits. 100+ books a year improve my life. I'll list life-changing books you can read in a day. I hope you like them too.
Let's get started!
1) Seneca's Letters from a Stoic
One of my favorite philosophy books. Ryan Holiday, Naval Ravikant, and other prolific readers recommend it.
Seneca wrote 124 letters at the end of his life after working for Nero. Death, friendship, and virtue are discussed.
It's worth rereading. When I'm in trouble, I consult Seneca.
It's brief. The book could be read in one day. However, use it for guidance during difficult times.

My favorite book quotes:
Many men find that becoming wealthy only alters their problems rather than solving them.
You will never be poor if you live in harmony with nature; you will never be wealthy if you live according to what other people think.
We suffer more frequently in our imagination than in reality; there are more things that are likely to frighten us than to crush us.
2) Steven Pressfield's book The War of Art
I’ve read this book twice. I'll likely reread it before 2022 is over.
The War Of Art is the best productivity book. Steven offers procrastination-fighting tips.
Writers, musicians, and creative types will love The War of Art. Workplace procrastinators should also read this book.

My favorite book quotes:
The act of creation is what matters most in art. Other than sitting down and making an effort every day, nothing else matters.
Working creatively is not a selfish endeavor or an attempt by the actor to gain attention. It serves as a gift for all living things in the world. Don't steal your contribution from us. Give us everything you have.
Fear is healthy. Fear is a signal, just like self-doubt. Fear instructs us on what to do. The more terrified we are of a task or calling, the more certain we can be that we must complete it.
3) Darren Hardy's The Compound Effect
The Compound Effect offers practical tips to boost productivity by 10x.
The author believes each choice shapes your future. Pizza may seem harmless. However, daily use increases heart disease risk.
Positive outcomes too. Daily gym visits improve fitness. Reading an hour each night can help you learn. Writing 1,000 words per day would allow you to write a novel in under a year.
Your daily choices affect compound interest and your future. Thus, better habits can improve your life.

My favorite book quotes:
Until you alter a daily habit, you cannot change your life. The key to your success can be found in the actions you take each day.
The hundreds, thousands, or millions of little things are what distinguish the ordinary from the extraordinary; it is not the big things that add up in the end.
Don't worry about willpower. Time to use why-power. Only when you relate your decisions to your aspirations and dreams will they have any real meaning. The decisions that are in line with what you define as your purpose, your core self, and your highest values are the wisest and most inspiring ones. To avoid giving up too easily, you must want something and understand why you want it.
You might also like
David Z. Morris
1 year ago
FTX's crash was no accident, it was a crime

Sam Bankman Fried (SDBF) is a legendary con man. But the NYT might not tell you that...
Since SBF's empire was revealed to be a lie, mainstream news organizations and commentators have failed to give readers a straightforward assessment. The New York Times and Wall Street Journal have uncovered many key facts about the scandal, but they have also soft-peddled Bankman-Fried's intent and culpability.
It's clear that the FTX crypto exchange and Alameda Research committed fraud to steal money from users and investors. That’s why a recent New York Times interview was widely derided for seeming to frame FTX’s collapse as the result of mismanagement rather than malfeasance. A Wall Street Journal article lamented FTX's loss of charitable donations, bolstering Bankman's philanthropic pose. Matthew Yglesias, court chronicler of the neoliberal status quo, seemed to whitewash his own entanglements by crediting SBF's money with helping Democrats in 2020 – sidestepping the likelihood that the money was embezzled.
Many outlets have called what happened to FTX a "bank run" or a "run on deposits," but Bankman-Fried insists the company was overleveraged and disorganized. Both attempts to frame the fallout obscure the core issue: customer funds misused.
Because banks lend customer funds to generate returns, they can experience "bank runs." If everyone withdraws at once, they can experience a short-term cash crunch but there won't be a long-term problem.
Crypto exchanges like FTX aren't banks. They don't do bank-style lending, so a withdrawal surge shouldn't strain liquidity. FTX promised customers it wouldn't lend or use their crypto.
Alameda's balance sheet blurs SBF's crypto empire.
The funds were sent to Alameda Research, where they were apparently gambled away. This is massive theft. According to a bankruptcy document, up to 1 million customers could be affected.
In less than a month, reporting and the bankruptcy process have uncovered a laundry list of decisions and practices that would constitute financial fraud if FTX had been a U.S.-regulated entity, even without crypto-specific rules. These ploys may be litigated in U.S. courts if they enabled the theft of American property.
The list is very, very long.
The many crimes of Sam Bankman-Fried and FTX
At the heart of SBF's fraud are the deep and (literally) intimate ties between FTX and Alameda Research, a hedge fund he co-founded. An exchange makes money from transaction fees on user assets, but Alameda trades and invests its own funds.
Bankman-Fried called FTX and Alameda "wholly separate" and resigned as Alameda's CEO in 2019. The two operations were closely linked. Bankman-Fried and Alameda CEO Caroline Ellison were romantically linked.
These circumstances enabled SBF's sin. Within days of FTX's first signs of weakness, it was clear the exchange was funneling customer assets to Alameda for trading, lending, and investing. Reuters reported on Nov. 12 that FTX sent $10 billion to Alameda. As much as $2 billion was believed to have disappeared after being sent to Alameda. Now the losses look worse.
It's unclear why those funds were sent to Alameda or when Bankman-Fried betrayed his depositors. On-chain analysis shows most FTX to Alameda transfers occurred in late 2021, and bankruptcy filings show both lost $3.7 billion in 2021.
SBF's companies lost millions before the 2022 crypto bear market. They may have stolen funds before Terra and Three Arrows Capital, which killed many leveraged crypto players.
FTT loans and prints
CoinDesk's report on Alameda's FTT holdings ignited FTX and Alameda Research. FTX created this instrument, but only a small portion was traded publicly; FTX and Alameda held the rest. These holdings were illiquid, meaning they couldn't be sold at market price. Bankman-Fried valued its stock at the fictitious price.
FTT tokens were reportedly used as collateral for loans, including FTX loans to Alameda. Close ties between FTX and Alameda made the FTT token harder or more expensive to use as collateral, reducing the risk to customer funds.
This use of an internal asset as collateral for loans between clandestinely related entities is similar to Enron's 1990s accounting fraud. These executives served 12 years in prison.
Alameda's margin liquidation exemption
Alameda Research had a "secret exemption" from FTX's liquidation and margin trading rules, according to legal filings by FTX's new CEO.
FTX, like other crypto platforms and some equity or commodity services, offered "margin" or loans for trades. These loans are usually collateralized, meaning borrowers put up other funds or assets. If a margin trade loses enough money, the exchange will sell the user's collateral to pay off the initial loan.
Keeping asset markets solvent requires liquidating bad margin positions. Exempting Alameda would give it huge advantages while exposing other FTX users to hidden risks. Alameda could have kept losing positions open while closing out competitors. Alameda could lose more on FTX than it could pay back, leaving a hole in customer funds.
The exemption is criminal in multiple ways. FTX was fraudulently marketed overall. Instead of a level playing field, there were many customers.
Above them all, with shotgun poised, was Alameda Research.
Alameda front-running FTX listings
Argus says there's circumstantial evidence that Alameda Research had insider knowledge of FTX's token listing plans. Alameda was able to buy large amounts of tokens before the listing and sell them after the price bump.
If true, these claims would be the most brazenly illegal of Alameda and FTX's alleged shenanigans. Even if the tokens aren't formally classified as securities, insider trading laws may apply.
In a similar case this year, an OpenSea employee was charged with wire fraud for allegedly insider trading. This employee faces 20 years in prison for front-running monkey JPEGs.
Huge loans to executives
Alameda Research reportedly lent FTX executives $4.1 billion, including massive personal loans. Bankman-Fried received $1 billion in personal loans and $2.3 billion for an entity he controlled, Paper Bird. Nishad Singh, director of engineering, was given $543 million, and FTX Digital Markets co-CEO Ryan Salame received $55 million.
FTX has more smoking guns than a Texas shooting range, but this one is the smoking bazooka – a sign of criminal intent. It's unclear how most of the personal loans were used, but liquidators will have to recoup the money.
The loans to Paper Bird were even more worrisome because they created another related third party to shuffle assets. Forbes speculates that some Paper Bird funds went to buy Binance's FTX stake, and Paper Bird committed hundreds of millions to outside investments.
FTX Inner Circle: Who's Who
That included many FTX-backed VC funds. Time will tell if this financial incest was criminal fraud. It fits Bankman-pattern Fried's of using secret flows, leverage, and funny money to inflate asset prices.
FTT or loan 'bailouts'
Also. As the crypto bear market continued in 2022, Bankman-Fried proposed bailouts for bankrupt crypto lenders BlockFi and Voyager Digital. CoinDesk was among those deceived, welcoming SBF as a J.P. Morgan-style sector backstop.
In a now-infamous interview with CNBC's "Squawk Box," Bankman-Fried referred to these decisions as bets that may or may not pay off.
But maybe not. Bloomberg's Matt Levine speculated that FTX backed BlockFi with FTT money. This Monopoly bailout may have been intended to hide FTX and Alameda liabilities that would have been exposed if BlockFi went bankrupt sooner. This ploy has no name, but it echoes other corporate frauds.
Secret bank purchase
Alameda Research invested $11.5 million in the tiny Farmington State Bank, doubling its net worth. As a non-U.S. entity and an investment firm, Alameda should have cleared regulatory hurdles before acquiring a U.S. bank.
In the context of FTX, the bank's stake becomes "ominous." Alameda and FTX could have done more shenanigans with bank control. Compare this to the Bank for Credit and Commerce International's failed attempts to buy U.S. banks. BCCI was even nefarious than FTX and wanted to buy U.S. banks to expand its money-laundering empire.
The mainstream's mistakes
These are complex and nuanced forms of fraud that echo traditional finance models. This obscurity helped Bankman-Fried masquerade as an honest player and likely kept coverage soft after the collapse.
Bankman-Fried had a scruffy, nerdy image, like Mark Zuckerberg and Adam Neumann. In interviews, he spoke nonsense about an industry full of jargon and complicated tech. Strategic donations and insincere ideological statements helped him gain political and social influence.
SBF' s'Effective' Altruism Blew Up FTX
Bankman-Fried has continued to muddy the waters with disingenuous letters, statements, interviews, and tweets since his con collapsed. He's tried to portray himself as a well-intentioned but naive kid who made some mistakes. This is a softer, more pernicious version of what Trump learned from mob lawyer Roy Cohn. Bankman-Fried doesn't "deny, deny, deny" but "confuse, evade, distort."
It's mostly worked. Kevin O'Leary, who plays an investor on "Shark Tank," repeats Bankman-SBF's counterfactuals. O'Leary called Bankman-Fried a "savant" and "probably one of the most accomplished crypto traders in the world" in a Nov. 27 interview with Business Insider, despite recent data indicating immense trading losses even when times were good.
O'Leary's status as an FTX investor and former paid spokesperson explains his continued affection for Bankman-Fried despite contradictory evidence. He's not the only one promoting Bankman-Fried. The disgraced son of two Stanford law professors will defend himself at Wednesday's DealBook Summit.
SBF's fraud and theft rival those of Bernie Madoff and Jho Low. Whether intentionally or through malign ineptitude, the fraud echoes Worldcom and Enron.
The Perverse Impacts of Anti-Money-Laundering
The principals in all of those scandals wound up either sentenced to prison or on the run from the law. Sam Bankman-Fried clearly deserves to share their fate.
Read the full article here.

Will Lockett
1 year ago
The Unlocking Of The Ultimate Clean Energy

The company seeking 24/7 ultra-powerful solar electricity.
We're rushing to adopt low-carbon energy to prevent a self-made doomsday. We're using solar, wind, and wave energy. These low-carbon sources aren't perfect. They consume large areas of land, causing habitat loss. They don't produce power reliably, necessitating large grid-level batteries, an environmental nightmare. We can and must do better than fossil fuels. Longi, one of the world's top solar panel producers, is creating a low-carbon energy source. Solar-powered spacecraft. But how does it work? Why is it so environmentally harmonious? And how can Longi unlock it?
Space-based solar makes sense. Satellites above Medium Earth Orbit (MEO) enjoy 24/7 daylight. Outer space has no atmosphere or ozone layer to block the Sun's high-energy UV radiation. Solar panels can create more energy in space than on Earth due to these two factors. Solar panels in orbit can create 40 times more power than those on Earth, according to estimates.
How can we utilize this immense power? Launch a geostationary satellite with solar panels, then beam power to Earth. Such a technology could be our most eco-friendly energy source. (Better than fusion power!) How?
Solar panels create more energy in space, as I've said. Solar panel manufacture and grid batteries emit the most carbon. This indicates that a space-solar farm's carbon footprint (which doesn't need a battery because it's a constant power source) might be over 40 times smaller than a terrestrial one. Combine that with carbon-neutral launch vehicles like Starship, and you have a low-carbon power source. Solar power has one of the lowest emissions per kWh at 6g/kWh, so space-based solar could approach net-zero emissions.
Space solar is versatile because it doesn't require enormous infrastructure. A space-solar farm could power New York and Dallas with the same efficiency, without cables. The satellite will transmit power to a nearby terminal. This allows an energy system to evolve and adapt as the society it powers changes. Building and maintaining infrastructure can be carbon-intensive, thus less infrastructure means less emissions.
Space-based solar doesn't destroy habitats, either. Solar and wind power can be engineered to reduce habitat loss, but they still harm ecosystems, which must be restored. Space solar requires almost no land, therefore it's easier on Mother Nature.
Space solar power could be the ultimate energy source. So why haven’t we done it yet?
Well, for two reasons: the cost of launch and the efficiency of wireless energy transmission.
Advances in rocket construction and reusable rocket technology have lowered orbital launch costs. In the early 2000s, the Space Shuttle cost $60,000 per kg launched into LEO, but a SpaceX Falcon 9 costs only $3,205. 95% drop! Even at these low prices, launching a space-based solar farm is commercially questionable.
Energy transmission efficiency is half of its commercial viability. Space-based solar farms must be in geostationary orbit to get 24/7 daylight, 22,300 miles above Earth's surface. It's a long way to wirelessly transmit energy. Most laser and microwave systems are below 20% efficient.
Space-based solar power is uneconomical due to low efficiency and high deployment costs.
Longi wants to create this ultimate power. But how?
They'll send solar panels into space to develop space-based solar power that can be beamed to Earth. This mission will help them design solar panels tough enough for space while remaining efficient.
Longi is a Chinese company, and China's space program and universities are developing space-based solar power and seeking commercial partners. Xidian University has built a 98%-efficient microwave-based wireless energy transmission system for space-based solar power. The Long March 5B is China's super-cheap (but not carbon-offset) launch vehicle.
Longi fills the gap. They have the commercial know-how and ability to build solar satellites and terrestrial terminals at scale. Universities and the Chinese government have transmission technology and low-cost launch vehicles to launch this technology.
It may take a decade to develop and refine this energy solution. This could spark a clean energy revolution. Once operational, Longi and the Chinese government could offer the world a flexible, environmentally friendly, rapidly deployable energy source.
Should the world adopt this technology and let China control its energy? I'm not very political, so you decide. This seems to be the beginning of tapping into this planet-saving energy source. Forget fusion reactors. Carbon-neutral energy is coming soon.
James Brockbank
1 year ago
Canonical URLs for Beginners
Canonicalization and canonical URLs are essential for SEO, and improper implementation can negatively impact your site's performance.
Canonical tags were introduced in 2009 to help webmasters with duplicate or similar content on multiple URLs.
To use canonical tags properly, you must understand their purpose, operation, and implementation.
Canonical URLs and Tags
Canonical tags tell search engines that a certain URL is a page's master copy. They specify a page's canonical URL. Webmasters can avoid duplicate content by linking to the "canonical" or "preferred" version of a page.
How are canonical tags and URLs different? Can these be specified differently?
Tags
Canonical tags are found in an HTML page's head></head> section.
<link rel="canonical" href="https://www.website.com/page/" />These can be self-referencing or reference another page's URL to consolidate signals.
Canonical tags and URLs are often used interchangeably, which is incorrect.
The rel="canonical" tag is the most common way to set canonical URLs, but it's not the only way.
Canonical URLs
What's a canonical link? Canonical link is the'master' URL for duplicate pages.
In Google's own words:
A canonical URL is the page Google thinks is most representative of duplicate pages on your site.
— Google Search Console Help
You can indicate your preferred canonical URL. For various reasons, Google may choose a different page than you.
When set correctly, the canonical URL is usually your specified URL.
Canonical URLs determine which page will be shown in search results (unless a duplicate is explicitly better for a user, like a mobile version).
Canonical URLs can be on different domains.
Other ways to specify canonical URLs
Canonical tags are the most common way to specify a canonical URL.
You can also set canonicals by:
Setting the HTTP header rel=canonical.
All pages listed in a sitemap are suggested as canonicals, but Google decides which pages are duplicates.
Redirects 301.
Google recommends these methods, but they aren't all appropriate for every situation, as we'll see below. Each has its own recommended uses.
Setting canonical URLs isn't required; if you don't, Google will use other signals to determine the best page version.
To control how your site appears in search engines and to avoid duplicate content issues, you should use canonicalization effectively.
Why Duplicate Content Exists
Before we discuss why you should use canonical URLs and how to specify them in popular CMSs, we must first explain why duplicate content exists. Nobody intentionally duplicates website content.
Content management systems create multiple URLs when you launch a page, have indexable versions of your site, or use dynamic URLs.
Assume the following URLs display the same content to a user:
A search engine sees eight duplicate pages, not one.
URLs #1 and #2: the CMS saves product URLs with and without the category name.
#3, #4, and #5 result from the site being accessible via HTTP, HTTPS, www, and non-www.
#6 is a subdomain mobile-friendly URL.
URL #7 lacks URL #2's trailing slash.
URL #8 uses a capital "A" instead of a lowercase one.
Duplicate content may also exist in URLs like:
https://www.website.com
https://www.website.com/index.php
Duplicate content is easy to create.
Canonical URLs help search engines identify different page variations as a single URL on many sites.
SEO Canonical URLs
Canonical URLs help you manage duplicate content that could affect site performance.
Canonical URLs are a technical SEO focus area for many reasons.
Specify URL for search results
When you set a canonical URL, you tell Google which page version to display.
Which would you click?
https://www.domain.com/page-1/
https://www.domain.com/index.php?id=2
First, probably.
Canonicals tell search engines which URL to rank.
Consolidate link signals on similar pages
When you have duplicate or nearly identical pages on your site, the URLs may get external links.
Canonical URLs consolidate multiple pages' link signals into a single URL.
This helps your site rank because signals from multiple URLs are consolidated into one.
Syndication management
Content is often syndicated to reach new audiences.
Canonical URLs consolidate ranking signals to prevent duplicate pages from ranking and ensure the original content ranks.
Avoid Googlebot duplicate page crawling
Canonical URLs ensure that Googlebot crawls your new pages rather than duplicated versions of the same one across mobile and desktop versions, for example.
Crawl budgets aren't an issue for most sites unless they have 100,000+ pages.
How to Correctly Implement the rel=canonical Tag
Using the header tag rel="canonical" is the most common way to specify canonical URLs.
Adding tags and HTML code may seem daunting if you're not a developer, but most CMS platforms allow canonicals out-of-the-box.
These URLs each have one product.
How to Correctly Implement a rel="canonical" HTTP Header
A rel="canonical" HTTP header can replace canonical tags.
This is how to implement a canonical URL for PDFs or non-HTML documents.
You can specify a canonical URL in your site's.htaccess file using the code below.
<Files "file-to-canonicalize.pdf"> Header add Link "< http://www.website.com/canonical-page/>; rel=\"canonical\"" </Files>301 redirects for canonical URLs
Google says 301 redirects can specify canonical URLs.
Only the canonical URL will exist if you use 301 redirects. This will redirect duplicates.
This is the best way to fix duplicate content across:
HTTPS and HTTP
Non-WWW and WWW
Trailing-Slash and Non-Trailing Slash URLs
On a single page, you should use canonical tags unless you can confidently delete and redirect the page.
Sitemaps' canonical URLs
Google assumes sitemap URLs are canonical, so don't include non-canonical URLs.
This does not guarantee canonical URLs, but is a best practice for sitemaps.
Best-practice Canonical Tag
Once you understand a few simple best practices for canonical tags, spotting and cleaning up duplicate content becomes much easier.
Always include:
One canonical URL per page
If you specify multiple canonical URLs per page, they will likely be ignored.
Correct Domain Protocol
If your site uses HTTPS, use this as the canonical URL. It's easy to reference the wrong protocol, so check for it to catch it early.
Trailing slash or non-trailing slash URLs
Be sure to include trailing slashes in your canonical URL if your site uses them.
Specify URLs other than WWW
Search engines see non-WWW and WWW URLs as duplicate pages, so use the correct one.
Absolute URLs
To ensure proper interpretation, canonical tags should use absolute URLs.
So use:
<link rel="canonical" href="https://www.website.com/page-a/" />And not:
<link rel="canonical" href="/page-a/" />If not canonicalizing, use self-referential canonical URLs.
When a page isn't canonicalizing to another URL, use self-referencing canonical URLs.
Canonical tags refer to themselves here.
Common Canonical Tags Mistakes
Here are some common canonical tag mistakes.
301 Canonicalization
Set the canonical URL as the redirect target, not a redirected URL.
Incorrect Domain Canonicalization
If your site uses HTTPS, don't set canonical URLs to HTTP.
Irrelevant Canonicalization
Canonicalize URLs to duplicate or near-identical content only.
SEOs sometimes try to pass link signals via canonical tags from unrelated content to increase rank. This isn't how canonicalization should be used and should be avoided.
Multiple Canonical URLs
Only use one canonical tag or URL per page; otherwise, they may all be ignored.
When overriding defaults in some CMSs, you may accidentally include two canonical tags in your page's <head>.
Pagination vs. Canonicalization
Incorrect pagination can cause duplicate content. Canonicalizing URLs to the first page isn't always the best solution.
Canonicalize to a 'view all' page.
How to Audit Canonical Tags (and Fix Issues)
Audit your site's canonical tags to find canonicalization issues.
SEMrush Site Audit can help. You'll find canonical tag checks in your website's site audit report.
Let's examine these issues and their solutions.
No Canonical Tag on AMP
Site Audit will flag AMP pages without canonical tags.
Canonicalization between AMP and non-AMP pages is important.
Add a rel="canonical" tag to each AMP page's head>.
No HTTPS redirect or canonical from HTTP homepage
Duplicate content issues will be flagged in the Site Audit if your site is accessible via HTTPS and HTTP.
You can fix this by 301 redirecting or adding a canonical tag to HTTP pages that references HTTPS.
Broken canonical links
Broken canonical links won't be considered canonical URLs.
This error could mean your canonical links point to non-existent pages, complicating crawling and indexing.
Update broken canonical links to the correct URLs.
Multiple canonical URLs
This error occurs when a page has multiple canonical URLs.
Remove duplicate tags and leave one.
Canonicalization is a key SEO concept, and using it incorrectly can hurt your site's performance.
Once you understand how it works, what it does, and how to find and fix issues, you can use it effectively to remove duplicate content from your site.